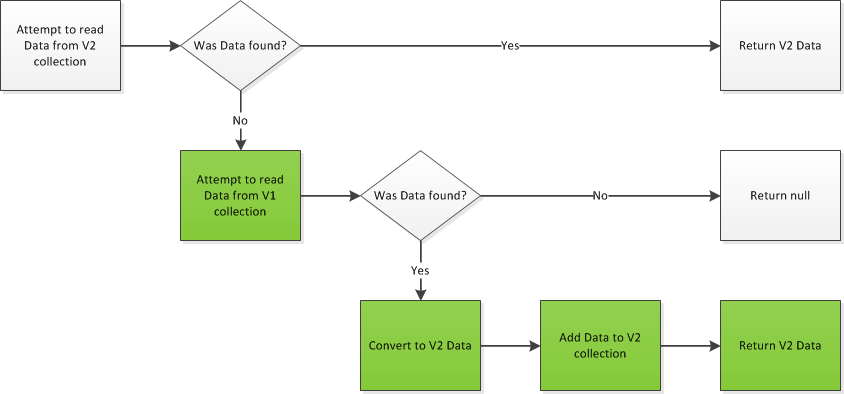
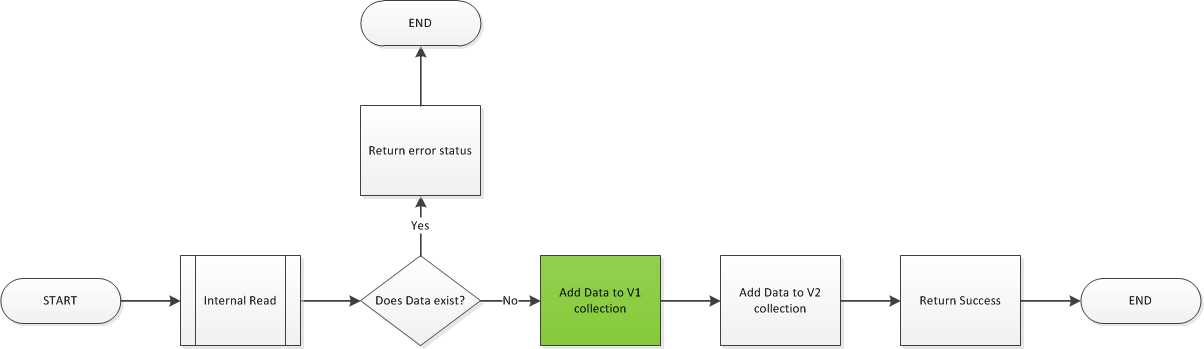
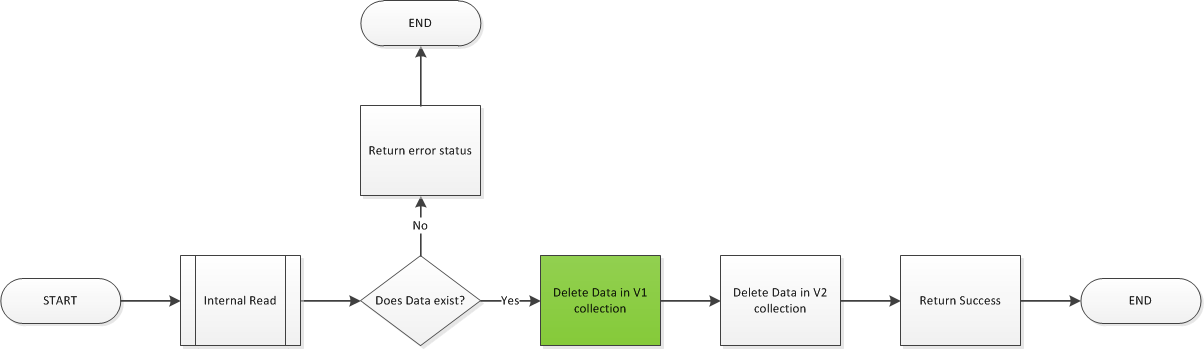
Automated Tests are important. People know this. But do they really know what matters when it comes to automated testing?
Well, let’s think about it. What are we trying to accomplish with our automated tests? We’re trying to make sure that the software we just wrote functions and that we didn’t break any existing functionality. But we can do that with manual tests. So what makes automated tests special? The main thing that makes them special is they are automated.
Automated Tests Must Actually Be Automated
I know this seems obvious, but you’d be surprised how easy it is to get this one wrong. For example, one place I worked had a suite of automated tests that had to be manually deployed (by a person), started (by a person), and then monitored (again, by a person). Not very automated, after all.
Automated Tests Must Actually Test the Program
Code coverage and relevance are probably some of the hardest testing concepts to get right. Wanna know why? Because there’s not a definite right answer. The normal target number for code coverage is 80%, but if you’re writing tests just to cover lines and not actually exercise functionality then that number is meaningless. Relevance is more critical than coverage, but there’s no objective way to really measure it. Just making sure you have tests for all the requirements or acceptance criteria is probably a good place to start. After that, just target important sections and give them some extra love.
Automated Tests Must Be Deterministic
If one of your solutions to test failures is, ” run it again,” then you have a problem here. If I give the same test the same inputs, then i should get the same results every time. Automated tests should only fail because the code is bad, not because the tests are bad.
What About Unit vs. Non-unit Tests
Unit tests are good because it’s easy to make them fit all the criteria. But if you can have integrated tests or functional tests that fit the criteria, then use them. In fact, it would probably be a good strategy to mix them all in together. The more tests, the better. Don’t worry about whether or not you’ve truly isolated your test to a unit, worry instead that your code will work, and if it doesn’t then a test will tell you.
So, get out there and write some tests. Hopefully, they’re automated. But if not, write them anyway. Just write some.